Here is part 1: FreeCAD Tutorial Office Chair Part 1: Setup and Constraints
Or go to the previous part.
While You Were Away …
I fixed the transparency and the hard edges of the joint plus renamed a few nodes:

Here is the file: Office Chair Tutorial Part 04 Start
The Base
The base of our chair should have five struts and hole to support the gas spring:
Struts
Create a new body, call it “Strut”.
Create a sketch, use the same plane as the joint (YZ Plane).
You should end up with this:

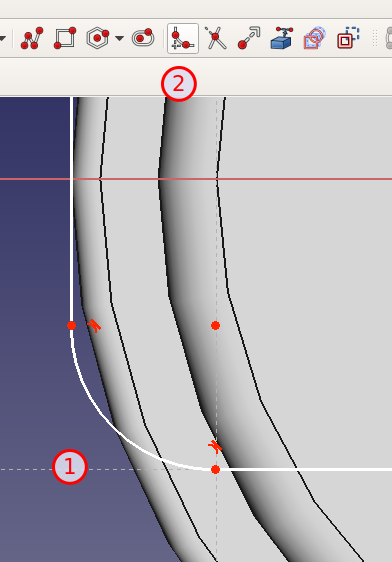
Draw a corner around the vertical joint axis:

For the arching strut, we’re going to use two B-splines with control points. For each arch, create three control points (so the whole spline should have 5 points):

Those “fans” look weird, right?
Those visualize how “bent” the spline is (= speed of change of direction, longer lines = faster change). If you have nicks in those curves (like above), it can mean trouble. Let’s ignore those fans for now.
Note how I created a sharper bend by moving two control points closer together (lower spline, two control points to the left).
Make sure that the left end points of both arches are constrained to the end points of the corner.
Keeping Stuff in Place
One thing I would like to do is to constrain the “joint end” of the strut to the “Vertical Rotation Center” which we created in the joint. That way, the strut will keep it’s position relative to the axis of the joint. The problem is that this datum line is part of the “Rotating Joint” body.
To change this:
- Close the (incomplete) sketch.
- Right-click the node “Vertical Rotation Center” (below “Rotating Joint”)
- Select “Copy”
- In the dialog “Object dependencies”, chose “No” (don’t copy the “Vertical Joint Axis”, too)
- Right-click “Strut”
- Select “Paste”
- Rename the new node to “Vertical Rotation Center Copy”

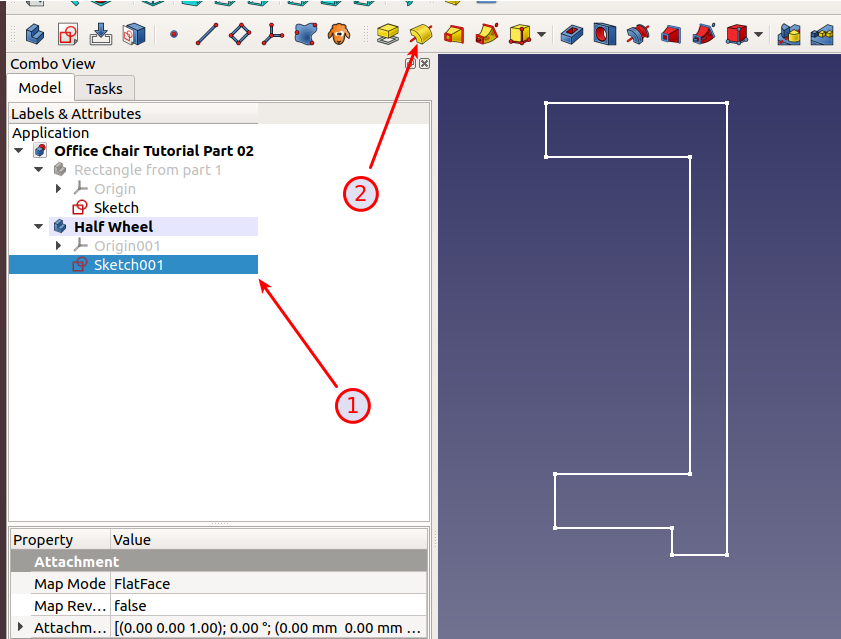
Double click “Sketch006” to continue working on it.
Try to apply a horizontal constraint between the bottom left edge and the datum line.
Turns out, we can’t select the datum line … now what?
Let’s try a “local coordinate system”.
- Close the sketch
- Make sure “Strut” is active
- Select “Office Chair Tutorial Part 04” in the tree
- Create a local coordinate system
- Select the ring we used as base for the datum line (where the axis and the joint meet)

Hm …. I would prefer the Z axis to go “up”. To achieve this, check “Flip sides”:

Nice. Click “OK” to create the coordinate system.
You’ll get this dialog:

Remember we selected the circle? It’s part of the joint body. FreeCAD now wonders how we want to handle this situation. Do we want to create something which will stay put when we change the joint? Or maybe we just want to use the new coordinate system in the body it references (dependent copy)? Or should changes to the joint move the coordinate system?
We want to last of the options since one end of the arch should stay where the joint is. Select “Create cross-reference” and “OK”.
Hm … there doesn’t seem to be a way to use the new coordinate system in the existing sketch.
I also can’t find a way to use it in a new sketch.
The sketch always asks for a plane. The toolbar offers a datum plane, let’s try that.
I again select the circle, attachment mode is “Concentric” but the new plane is coplanar (= in the same plane) with the circle. We need something that is perpendicular to the circle. Flip sides won’t help this time, set “Roll” to “90 °”:

The orientation looks good but what about the origin? From the preview, the plane seems to be way to far up/right. Let’s hope for the best. OK, “Create cross-reference”, OK.
Create a new sketch and now ,we can select our now DatumPlane:
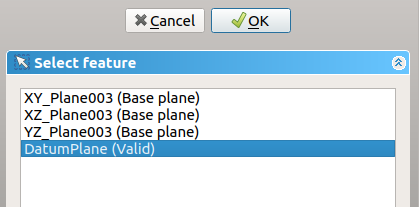
Hm. Why is everything upside down?

3D is annoying. I bet this is because of our 90 ° roll. Edit the plane, select “Flip sides”. If we create a new sketch, this looks much better:
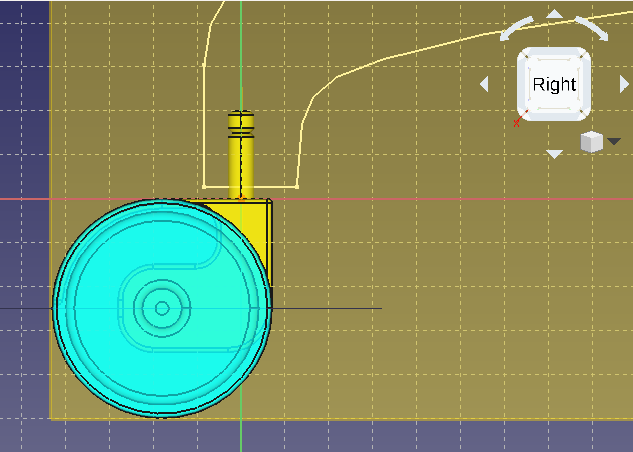
What about our existing geometry? I couldn’t find a way to copy the elements and constraints over, so they are lost. Just make the old sketch visible and draw something similar.
Now for the big moment: Will the constraints use the new origin?
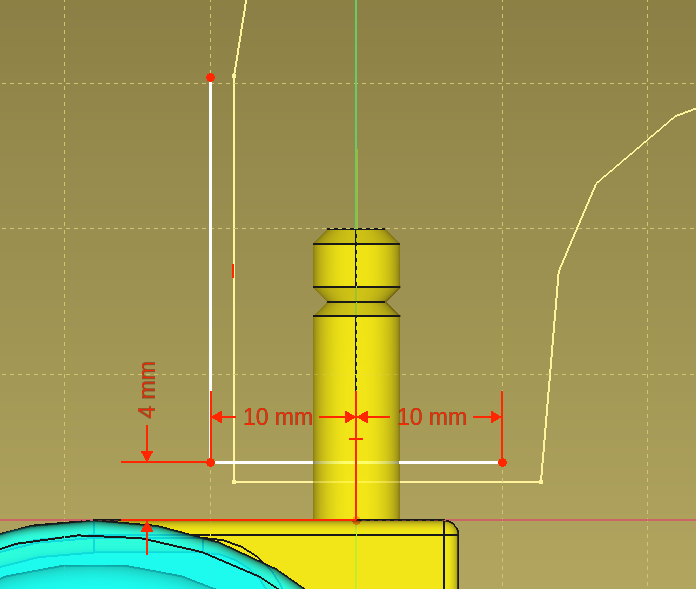
Yes!
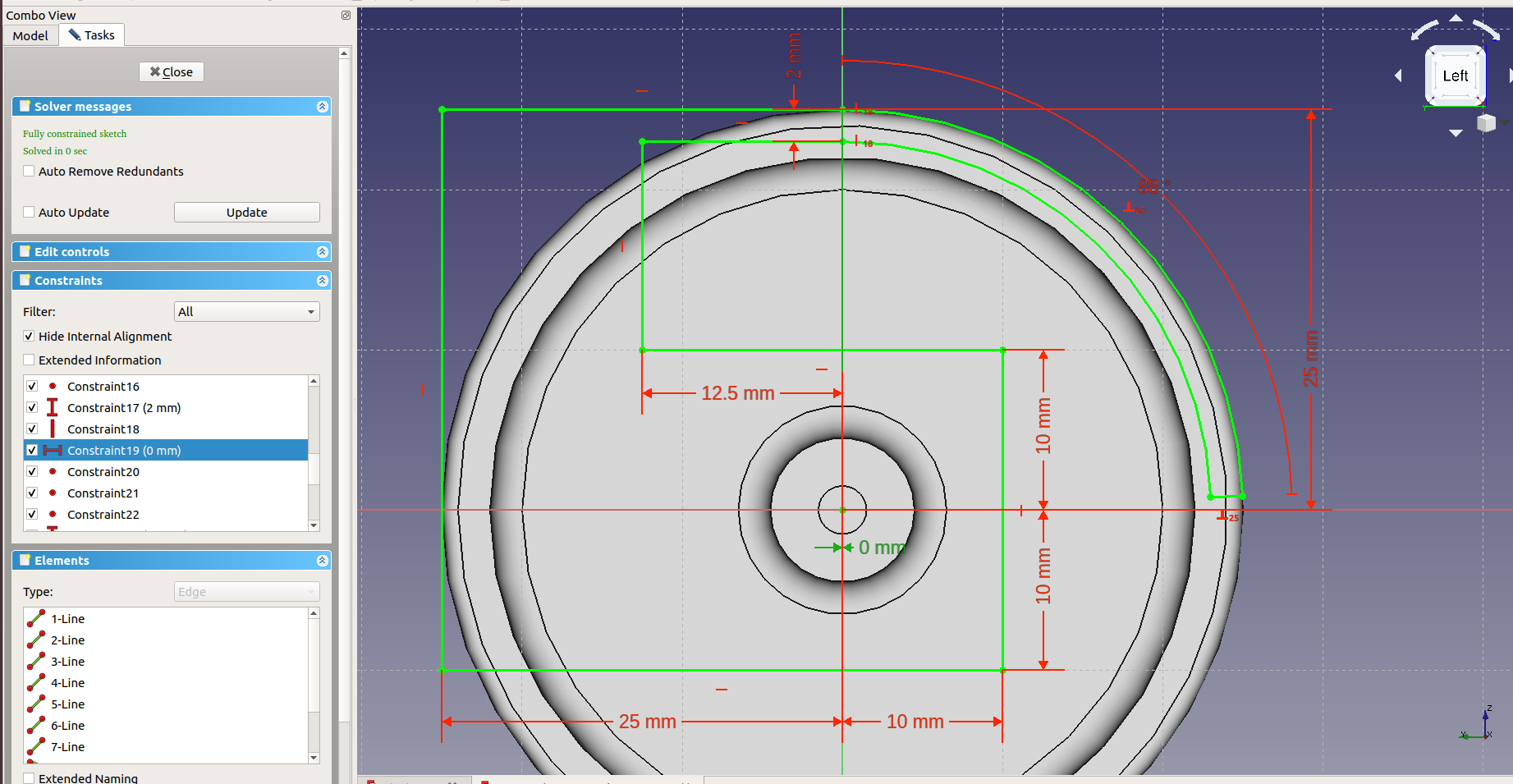
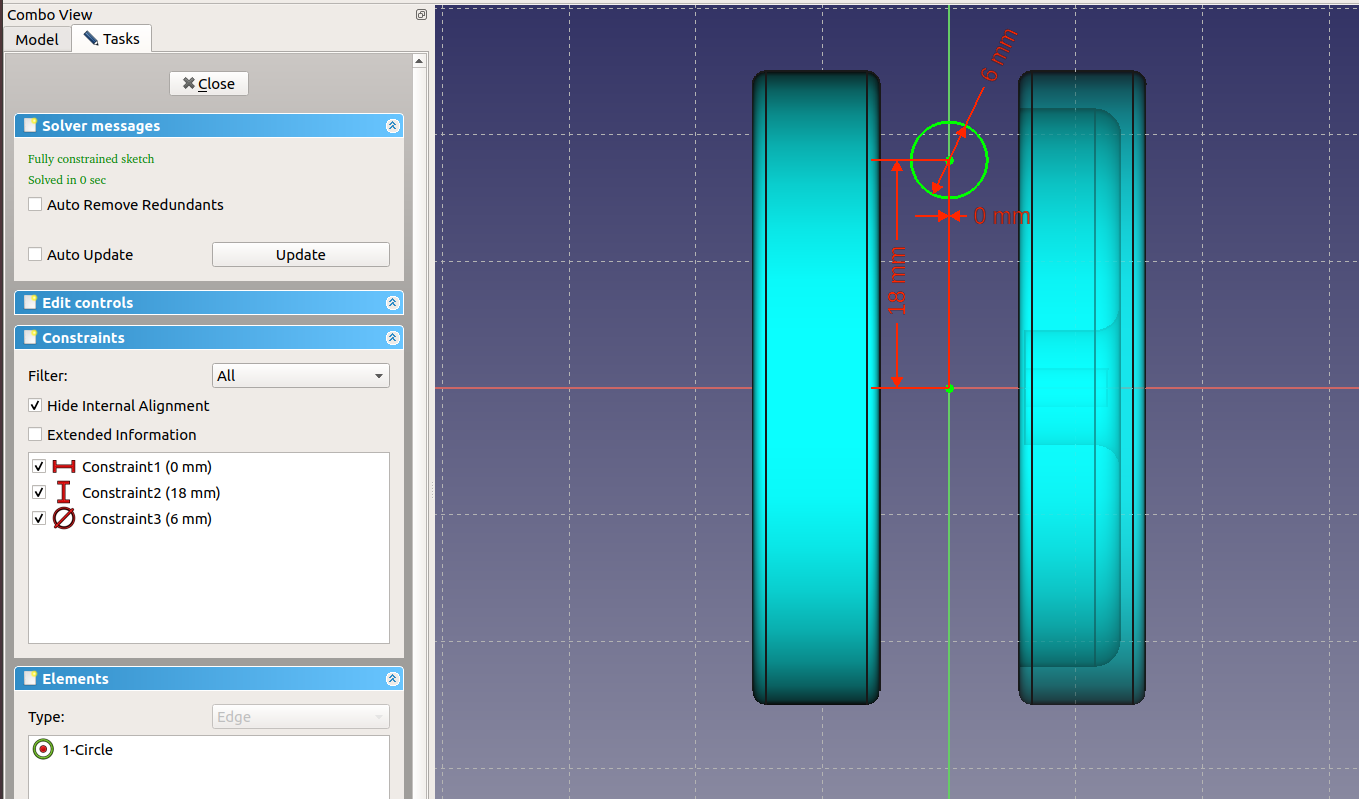
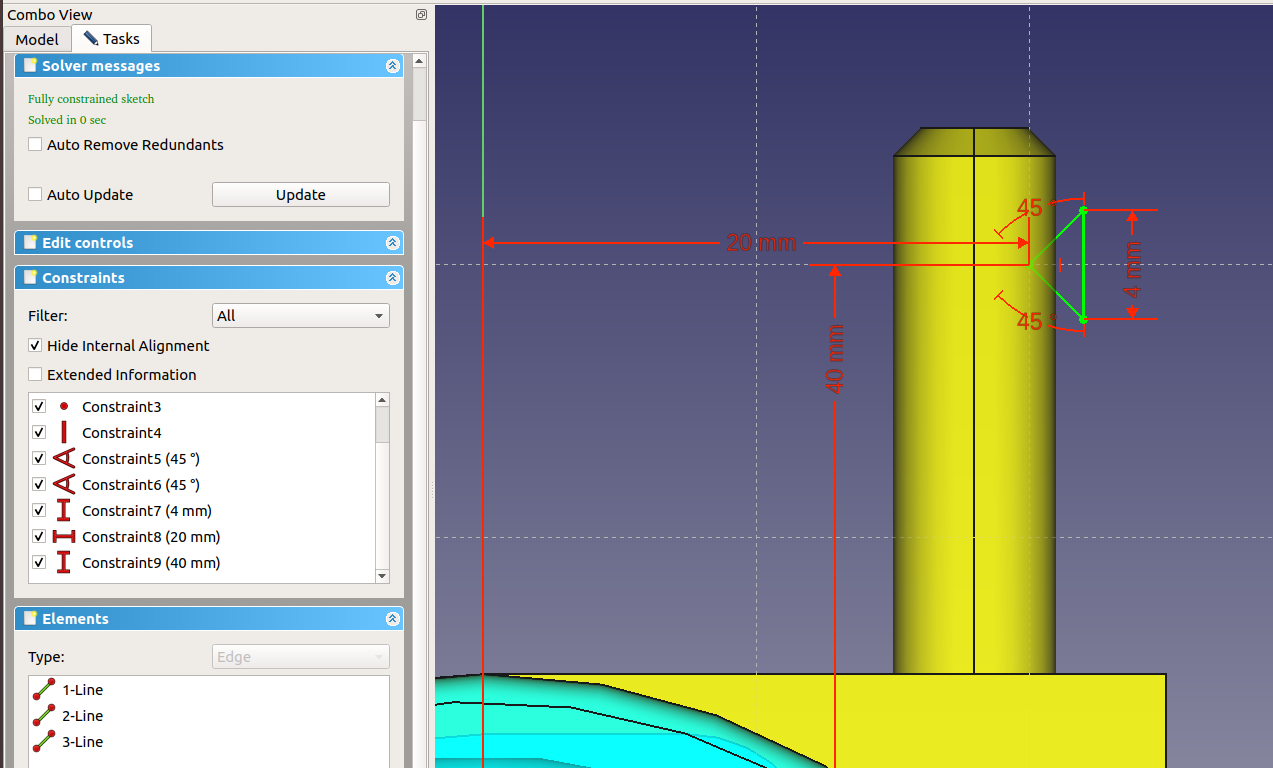
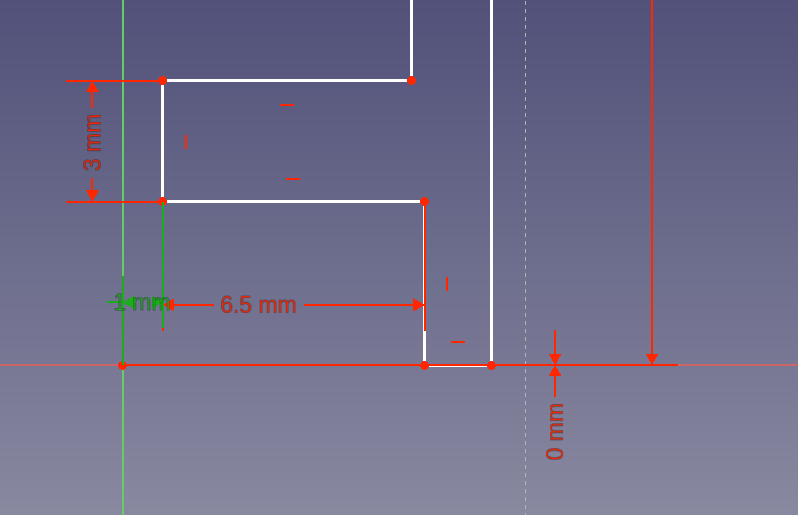
Working from left to right, I get this fully constrained sketch:

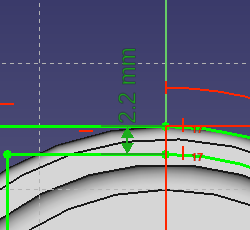
The blue distance at the bottom is a constraint in “reference mode” which basically means it just shows a value but doesn’t take part of the solution process:
- Toggle to reference mode. Some constraints will turn blue.
- Take the blue “Horizontal distance” tool and select points at the ends of the strut.
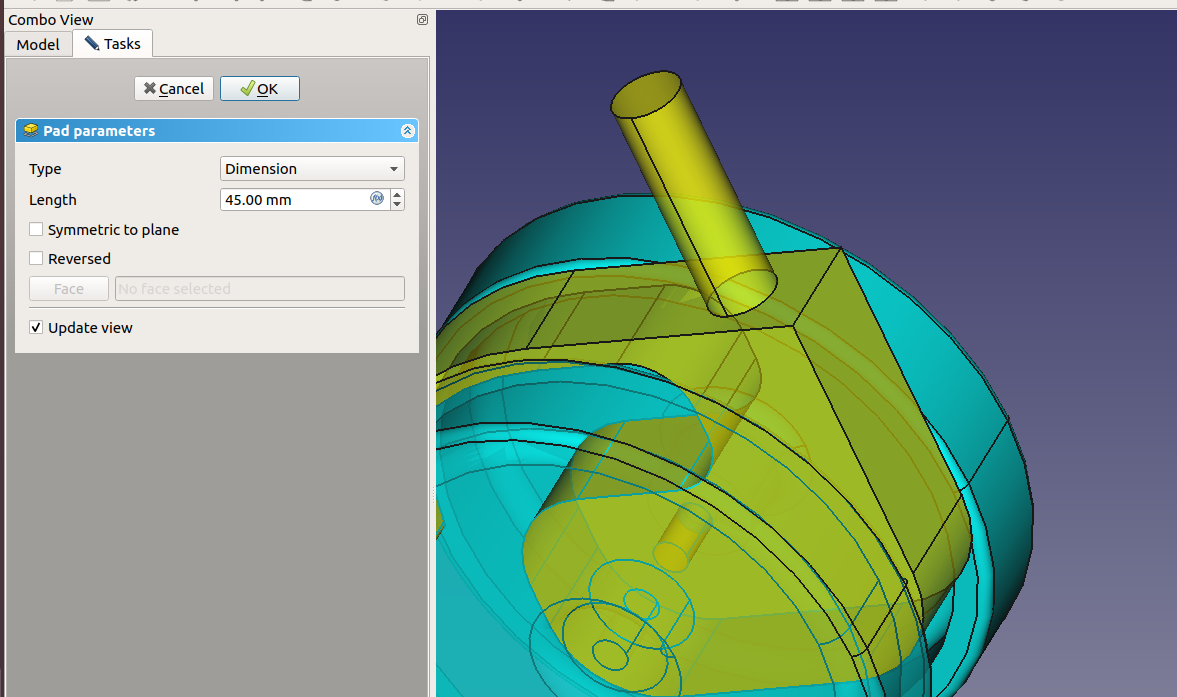
Close the sketch and pad it, 10 mm, symmetric to plane plus some fillets gives me:

Socket for Gas Spring
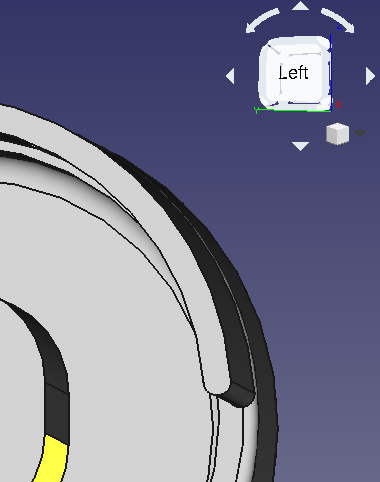
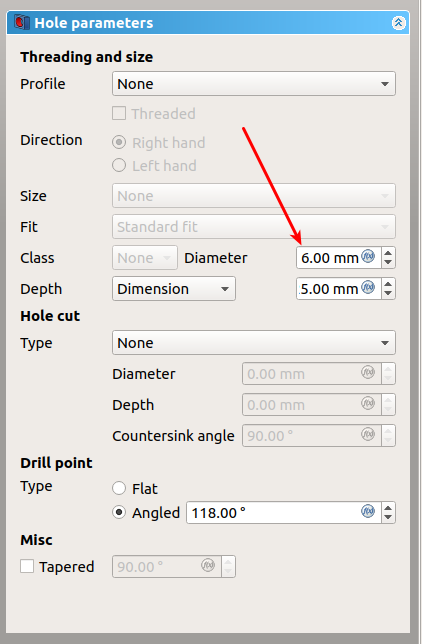
For the central socket, we need another datum plane at the far end of the strut. Otherwise, attaching the chair to the base would be complicated.
Note: Another solution would be to join all parts in a compound and then move the compound around until the upper end of the strut is near the origin (right now, it’s just the other way around).
Note 2: Before you design something complicated, you may want to figure out a good place for your origin. Our situation happened because I chose to build the first foot around the origin.
The new datum plane is parallel to the first one but shifted to the right (= positive along the X axis)
I tried several ways to achieve this but I have a feeling that creating work / datum planes is not designed very well at the moment. There are lots of complicated options but nothing that really works well.
In the end, I used this complicated mess:

I selected “Plane face” as mode, then clicked on the yellow face. I created a sketch based on this plane. Jumping back and forth between the sketch and the plane, I played with the attachment offsets until it was kind of where I wanted it:

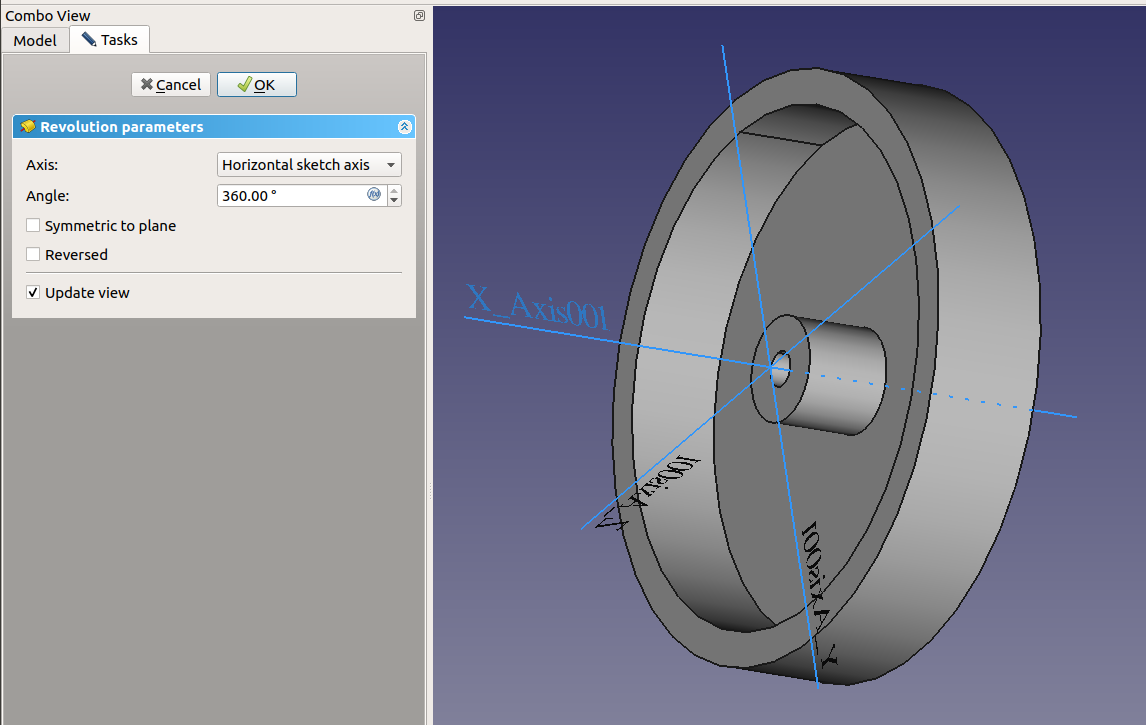
One revolve and a few fillets later, I had this:

Getting Five Struts From One
The last step is to make five copies of the strut plus foot.
While I could use copy & paste, the copies would be independent. So no change I made to the original would propagate. To solve this, there is a Array tool. This tool can create copies and arrange them, too.
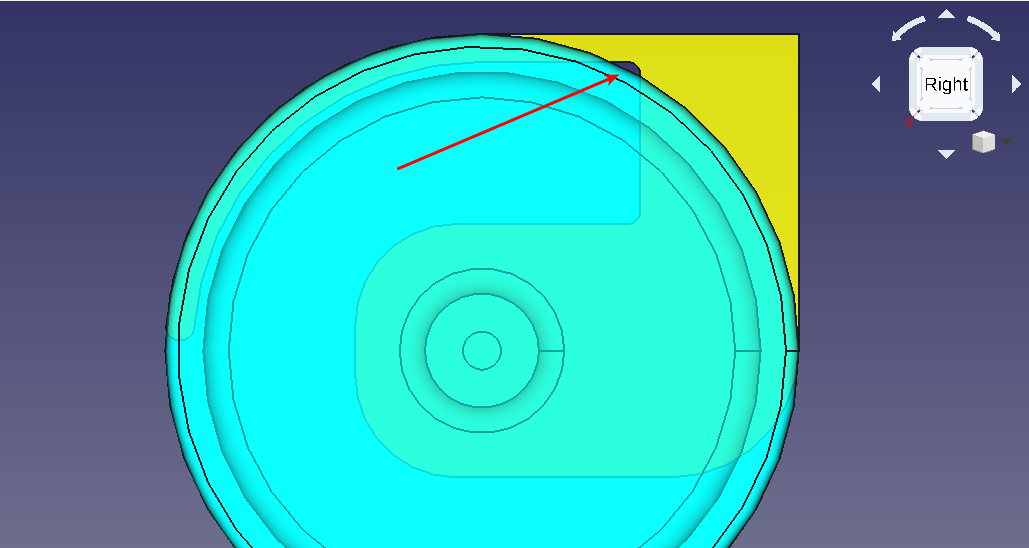
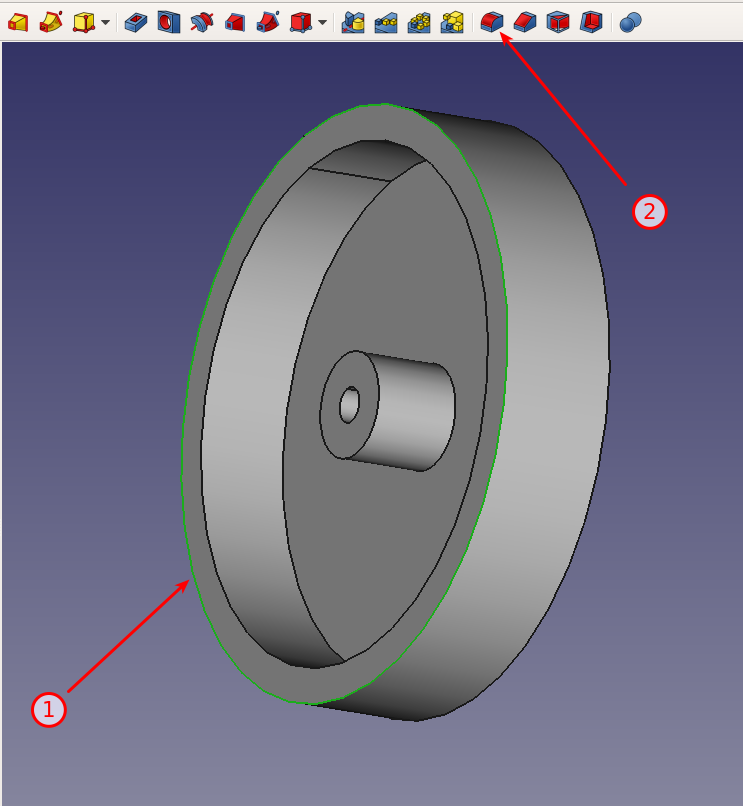
As rotation axis, we need a datum line. Select one of the circles around the socket:

Click OK.
Since we want to copy three bodies (wheels, joint and strut), we first need to combine them into one body.
- Switch to “Part” workbench
- Select “Dual Wheel” and “Rotating Joint” in the tree
- Click “Make Compound”
- Rename the new node to “Joint with wheels”
- Select “Joint with wheels” and “Strut”
- Click “Make Compound”
- Rename the new node to “Strut with foot”
Your tree should now look like so:

To create five copies:
- Switch to “Draft” workbench.
- Select the node “Strut with foot”
- Click the menu “Draft” / “Array”
At least in my version of FreeCAD, this didn’t have a dialog or panel to configure the array. Instead, you get this:
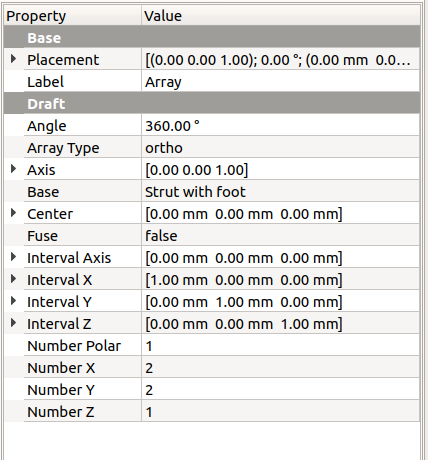
Change these values:
- Put “polar” into “Array Type”
- Put “1” into “Number X” and “Number Y”
- Put “5” into “Number Polar”
You’ll get this:

Remember when I said that it’s important to decide where to put the origin? That’s why.
Also, there is no way to select a rotation axis (the datum line from above).
How to fix this?
One way is to move the “Strut with foot” so that it’s other end is near the origin. This can be done by changing the “Position”. On my case, the y value:

Okay … better … I guess. What’s with the wheel at the center? Doesn’t want to play with the rest?
Enough for today. Here is the file if you want to fix it yourself: Office Chair Tutorial Part 04



 Posted by digulla
Posted by digulla 


















































Artificial Ethics
24. October, 2017While watching this video, I wondered: We’re using machine learning to earn money on the stock market and to make computers understand speech. Why not ethics?
Around @26:00 , Isaac talks about ways to develop AIs to control androids. He would like to use the safe approach of manual programming all the specific details to create an AI.
The “manual programming” path has been tried since 1960 and it’s now deemed a failure. The task is simply too complex. It’s like manually writing down all possible chess positions: Even if you tried, you’d run out of time. Machine learning is the way to go.
Which means we have to solve a “simple” problem: Encode the rules of ethics. That is, a machine learning algorithm must check itself (or be checked by another algorithm) against a basic set of ethical rules to determine whether “a solution” to “a problem” is “ethical” (quotes mean: “We still have to figure out exactly what that means and how to put it into code”).
Just like intelligence, ethics is somewhat of a soft and moving target. Fortunately, we have a huge body of texts (religious, laws, philosophy, polls) which a machine learning algorithm could be trained on. To test this machine, we could present it with artificial and real life incidents and see how it rules. Note: The output of this algorithm would be a number between 0 (very unethical) and 1 (very ethical). It would not spit out solutions on how to solve an ethical dilemma. It could just judge an existing solution.
It’s important that the output (judgement) is checked and the result (how good the output was) is fed back into the algorithm so it can tune itself. Both output and feedback needs to be checked for the usual problems (racism, prejudice, etc.).
Based on that, another machine learning algorithm (MLA) could then try many different solutions, present those to the ethics one, and pick the best ones. At the beginning, humans would supervise this process as well (feedback as above). Eventually, the MLA would figure out the hidden rules of good solutions.
That would eventually lead to ethical machines. Which would cause new problems: There will eventually be a machine, very impartial, that “is” more ethical than almost all humans. Whatever “is” might mean, then.
Related articles:
Share this: